last updated 2020.07.30 : update for Jetpack 4.4
I used Jetson Nano, Ubuntu 18.04 Official image with root account.
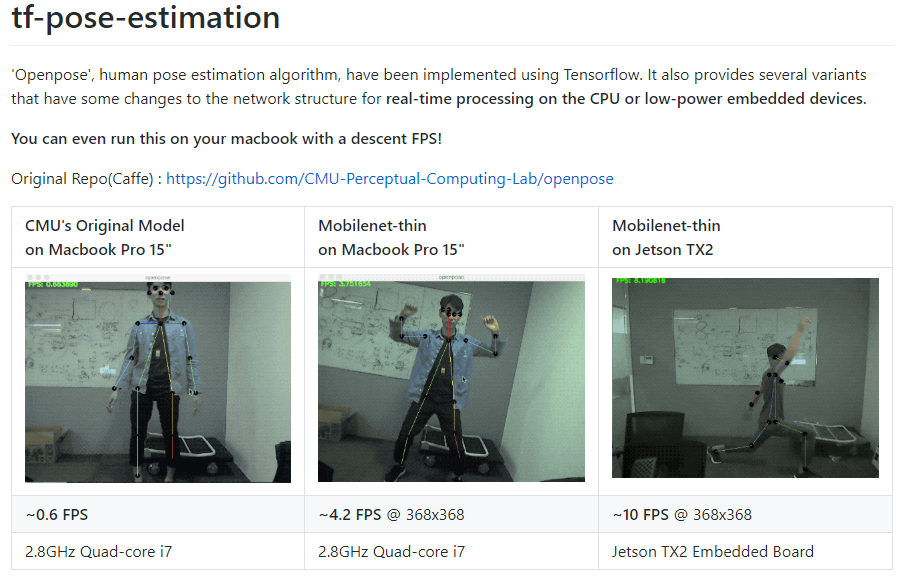
OpenPose(https://github.com/CMU-Perceptual-Computing-Lab/openpose) is one of the most popular pose estimation framework. You can install OpenPose on the Jetson Nano. But Jetson Nano's GPU power is not strong enough to run the OpenPose. It suffers from lack of memory, computing power.
There's a lightweight Pose Estimation Tensorflow framework(https://github.com/ildoonet/tf-pose-estimation). Let's install and do Pose Estimation.
Prerequisites
JetPack 4.3
If you are using JetPack 4.4, skip to the section below.
Before you build "ildoonet/tf-pose-estimation", you must pre install these packages. See the URLs.
- OpenCV : https://spyjetson.blogspot.com/2019/09/jetsonnano-opencv-411-build.html
- tensorflow : https://spyjetson.blogspot.com/2019/09/jetsonnano-installing-tensorflow-114.html
After installing above packages, install these packages too.
1 2 3 4 | apt-get install libllvm-7-ocaml-dev libllvm7 llvm-7 llvm-7-dev llvm-7-doc llvm-7-examples llvm-7-runtime apt-get install -y build-essential libatlas-base-dev swig gfortran export LLVM_CONFIG=/usr/bin/llvm-config-7 pip3 install Cython |
JetPack 4.4
- OpenCV : JetPack 4.3 and later versions have OpenCV installed. Therefore, there is no need to install OpenCV. Xavier NX has JetPack 4.4 or higher installed..
- Tensorflow : https://spyjetson.blogspot.com/2020/07/jetson-xavier-nx-python-virtual.html explains how to use the Python virtual environment and install TensorFlow.
After installing above packages, install these packages too.
Perhaps some of these packages are already installed. Previously, Jetson
Nano used llvm version 7, but JetPack 4.4 uses llvm
version 9.
Warning
: The scikit-image to be
installed later requires scipy 1.0.1 or higher. Therefore, upgrade the
scipy version . The pip3 install --upgrade scipy command will upgrade the scipy
version to 1.5.2.
apt-get install libllvm-9-ocaml-dev libllvm9 llvm-9 llvm-9-dev llvm-9-doc llvm-9-examples llvm-9-runtime
pip3 install --upgrade scipy apt-get install -y build-essential libatlas-base-dev swig gfortran export LLVM_CONFIG=/usr/bin/llvm-config-9
Download and build code from ildoonet
Now clone ildoonet's github.
Install Step #1
1 2 3 4 | cd /usr/local/src git clone https://www.github.com/ildoonet/tf-pose-estimation cd tf-pose-estimation pip3 install -r requirements.txt |
Edit Code
edit tf_pose/estimator.py file like this (based on Tensorflow 1.14)
original code
1 | self.persistent_sess = tf.Session(graph=self.graph, config=tf_config) |
to
1 2 3 4 5 6 | if tf_config is None: tf_config = tf.ConfigProto() tf_config.gpu_options.allow_growth = True sess = tf.Session(config=tf_config) self.persistent_sess = tf.Session(graph=self.graph, config=tf_config) |
And the source code has --tensorrt option to use TensorRT. To use this option, modify the ./tf_pose/estimator.py file.
At 327 line, remove the last parameter "use_calibration=True,". This parameter is deprecated Tensorflow version 1.14 or later.
At 327 line, remove the last parameter "use_calibration=True,". This parameter is deprecated Tensorflow version 1.14 or later.
Install Step #2
1 2 | cd tf_pose/pafprocess swig -python -c++ pafprocess.i && python3 setup.py build_ext --inplace |
Install Step #3(optional)
1 2 | cd /usr/local/src/study/tf-pose-estimation/models/graph/cmu
bash download.sh
|
Testing with image
There are pre made testing python files like run.py, run_video.py, run_webcam.pyYou can test the framework with images like this.
1 | $ python3 run.py --model=mobilenet_thin --resize=432x368 --image=./images/p1.jpg |

Wait for about several minutes. You can see the result images like this.

Poor performance
Does it take too much time for estimating a pose? Yes, but it's too early to disappoint. Most of deep learning frameworks load network model first, and it takes some time. After loading the model into memory, next step is fast.Under the hood
Now let's dig deeper.Webcam test
Let's test with a webcam to check the framework performance. You can use a Raspberry Pi CSI v2 camera or a USB webcam. I'll use a webcam. After connect a webcam, make sure it's connected properly. Use lsusb command, then find the webcam. I'm using a Logitech Webcam.
Check the Bus, Device values(001, 003). Then You can view the webcam's resolution like this.
lsusb -s 001:003 -v
or
lsusb -s 001:003 -v |grep -E "wWidth|wHeight"
Let's test several network models to compare the performance.
mobilenet_v2_small model test
First I'll test the mobilenet_v2_small network that is the most light model.python3 run_webcam.py --model=mobilenet_v2_small

The performance of mobilenet_v2_small is 1.2 ~ 3.9 fps(frame per seconds)
mobilenet_v2_large model test
python3 run_webcam.py --model=mobilenet_v2_large

The performance of mobilenet_v2_large is 2.5 fps(frame per seconds)
mobilenet_thin model test
python3 run_webcam.py --model=mobilenet_thin

The performance of mobilenet_thin is 1.5 ~ 3.1 fps(frame per seconds)
When Jetson Nano load three network models, loading mobilenet_thin takes the longest time, because the network size is bigger than others.
But after loading the network, three models show similar fps values.
I think the accuracy of pose estimation is lower than the OpenPose framework. But OpenPose on the JetsonNano can't make 1fps performance. So If you plan to make a realtime pose estimation program on the Jetson Nano, this framework would be your choice.
The following pictures are the results of testing using mobilenet-thin, mobilenet-v2-small and mobilenet-v2-large.
mobilenet-thin test images


mobilenet-v2-small test images


mobilenet-v2-large test images


Raise FPS Value
I tested webcan without --resize option. Default value is 432X368. If you use the --resize=368x368 option, the fps value will rise above 4.And the source code has --tensorrt option to use TensorRT. To use this option, modify the ./tf_pose/estimator.py file.
At 327 line, remove the last parameter "use_calibration=True,". This parameter is deprecated version 1.14.
To use TensorRT, I used --tensorrt option.
python3 run_webcam.py --model=mobilenet_thin --resize=368x368 --tensorrt=true
The program took longer to load because of TensorRT graph initializing. Disappointingly, however, fps did not change much. If you know how to solve it, please let me know.

Using KeyPoints
If you want to utilize this framework. you must know the keypoints position and its name(left shoulder, left eye, right knee, ...). Let's dig deeper.CoCo(Common Objects in Context) keypoints
CoCo uses 18(0 ~ 17) keypoints like this. From now on, keypoints and human parts mean the same thing.
Each number represents these human parts.
- Nose = 0
- Neck = 1
- RShoulder = 2
- RElbow = 3
- RWrist = 4
- LShoulder = 5
- LElbow = 6
- LWrist = 7
- RHip = 8
- RKnee = 9
- RAnkle = 10
- LHip = 11
- LKnee = 12
- LAnkle = 13
- REye = 14
- LEye = 15
- REar = 16
- LEar = 17
- Background = 18
Finding humans, keypoints from image.
You can find this line from the sample code run.py. This line insert the inference image to the network model and get the result. So the return value "humans" contains all the necessary information for the pose estimation.humans = e.inference(image, resize_to_default=(w > 0 and h > 0), upsample_size=args.resize_out_ratio)
humans return value is a dictionary(same as list but cannot modify the contents) type variable that contains Human class object. So its size means the number of human in the image.
I made 2 functions to simply the keypoint detection process. The first function returns part(keypoint) from human, keypoint number(0 ~ 17). And the second function returns keypoint position in the image from part.
''' hnum: 0 based human index pos : keypoint ''' def get_keypoint(humans, hnum, pos): #check invalid human index if len(humans) <= hnum: return None #check invalid keypoint. human parts may not contain certain ketpoint if pos not in humans[hnum].body_parts.keys(): return None part = humans[hnum].body_parts[pos] return part ''' return keypoint posution (x, y) in the image ''' def get_point_from_part(image, part): image_h, image_w = image.shape[:2] return (int(part.x * image_w + 0.5), int(part.y * image_h + 0.5))
Let's assume that we want to detect the keypoints of the first human(list index number = 0).
for i in range(18): part = get_keypoint(humans, 0, i) if part is None: continue pos = get_point_from_part(image, part) print('No:%d Name[%s] X:%d Y:%d Score:%f'%( part.part_idx, part.get_part_name(), pos[0] , pos[1] , part.score)) cv2.putText(image,str(part.part_idx), (pos[0] + 10, pos[1]), font, 0.5, (0,255,0), 2)
This code will find CoCo Keypoints 0 to 17 if it exists. Then it prints the keypoints' position and put keypoint number on the image.
I made a new sample python program run2.py at https://github.com/raspberry-pi-maker/NVIDIA-Jetson/tree/master/tf-pose-estimation .
Run this program like this.
python3 run2.py --image=./images/hong.jpg --model=mobilenet_v2_small
You can get the output image(mobilenet_v2_small.png) that contains the part number.

<input image:hong.jpg output image:mobilenet_v2_small.png>
And console outputs are like this
No:0 Name[CocoPart.Nose] X:247 Y:118 Score:0.852600 No:1 Name[CocoPart.Neck] X:247 Y:199 Score:0.710355 No:2 Name[CocoPart.RShoulder] X:196 Y:195 Score:0.666499 No:3 Name[CocoPart.RElbow] X:127 Y:204 Score:0.675835 No:4 Name[CocoPart.RWrist] X:108 Y:138 Score:0.676011 No:5 Name[CocoPart.LShoulder] X:295 Y:195 Score:0.631604 No:6 Name[CocoPart.LElbow] X:346 Y:167 Score:0.633020 No:7 Name[CocoPart.LWrist] X:325 Y:90 Score:0.448359 No:8 Name[CocoPart.RHip] X:208 Y:395 Score:0.553614 No:9 Name[CocoPart.RKnee] X:217 Y:541 Score:0.671879 No:10 Name[CocoPart.RAnkle] X:235 Y:680 Score:0.622787 No:11 Name[CocoPart.LHip] X:284 Y:387 Score:0.399417 No:12 Name[CocoPart.LKnee] X:279 Y:525 Score:0.639912 No:13 Name[CocoPart.LAnkle] X:279 Y:680 Score:0.594650 No:14 Name[CocoPart.REye] X:233 Y:106 Score:0.878417 No:15 Name[CocoPart.LEye] X:258 Y:106 Score:0.801265 No:16 Name[CocoPart.REar] X:221 Y:122 Score:0.596228 No:17 Name[CocoPart.LEar] X:279 Y:122 Score:0.821814
Detecting angle of keypoints
If you want to get the left elbow angle, keypoint 5,6,7 are necessary.
def angle_between_points( p0, p1, p2 ): a = (p1[0]-p0[0])**2 + (p1[1]-p0[1])**2 b = (p1[0]-p2[0])**2 + (p1[1]-p2[1])**2 c = (p2[0]-p0[0])**2 + (p2[1]-p0[1])**2 return math.acos( (a+b-c) / math.sqrt(4*a*b) ) * 180 /math.pi
You can see full code at https://github.com/raspberry-pi-maker/NVIDIA-Jetson/blob/master/tf-pose-estimation/run_angle.py
This is output of run_angle.py
left hand angle:167.333590 left elbow angle:103.512531 left knee angle:177.924974 left ankle angle:177.698663 right hand angle:126.365861 right elbow angle:98.628579 right knee angle:176.148932 right ankle angle:178.021761
Wrapping Up
Even though Jetson Nano's webcam fps value is not satisfying, I think you can use this framework on the realtime keyframe detection.I'll test this framework on the Jetson TX2 soon. Perhaps I can experience very high fps performance.
I installed this model on Xavier NX and posted what I tested on https://spyjetson.blogspot.com/2020/07/xavier-nx-human-pose-estimation-using.html. Xavier NX users should refer to this article.
More information on using the ResNet-101 model on the Xavier NX to improve accuracy than the model using MobileNet is provided at Jetson Xavier NX - Human Pose estimation using tensorflow (mpii)
If you want the most satisfactory human pose estimation performance on Jetson Nano, see the following article(https://spyjetson.blogspot.com/2019/12/jetsonnano-human-pose-estimation-using.html). NVIDIA team introduces human pose estimation using models optimized for TensorRT.